Voice AI Platform
Two-level orchestration for production voice agents — audio layer + cognitive engine
A multi-tenant voice AI platform with a two-level orchestration architecture: a transport-bound audio layer and a turn-based cognitive engine that scales independently.
One platform to build, test, and ship voice agents — end to end.
We built a complete Voice AI platform centered on a two-level orchestration architecture. The CallOrchestrator owns the audio layer — Twilio / Plivo / Exotel WebSockets, STT (Deepgram, Sarvam), VAD + barge-in, TTS (Sarvam, ElevenLabs, Deepgram), turn memory, and the LISTENING ↔ PROCESSING ↔ SPEAKING state machine. The FlowOrchestrator owns the cognitive layer — LLM intent dispatch, precedence policy, node executor loop, HTTP fetch routing, and idempotent DB state commits. Because cognition is transport-agnostic, the same FlowOrchestrator runs against telephony, in-browser voice tests via LiveKit WebRTC, and editor dry-runs with no transport at all. The platform ships with a visual flow builder (goals, intents, transitions, safety nodes), an AI flow builder that drafts flows from natural-language prompts, multi-tenant workspaces with API keys, per-tenant phone-number provisioning, a public /v1/* API with HMAC-signed webhooks, and full call observability (transcripts, latency breakdown, replay).
The bet: keep the audio layer and the cognitive layer separate. The audio layer is hard-real-time and transport-bound. The cognitive layer is turn-based and transport-agnostic. Keeping them apart means cognition can run against telephony, in-browser voice tests, or editor dry-runs without changing a line.
Three surfaces. One coherent platform.
Design conversation flows the way your team actually thinks.
Goals, intents, transitions, safety nodes — no code. Product, CX, and engineering iterate on the same canvas. Generate complete flows from a natural-language prompt with the built-in AI Builder.
- Goals · intents · transitions
- Safety + interrupt nodes
- AI Builder for prompt-to-flow
- Versioned drafts
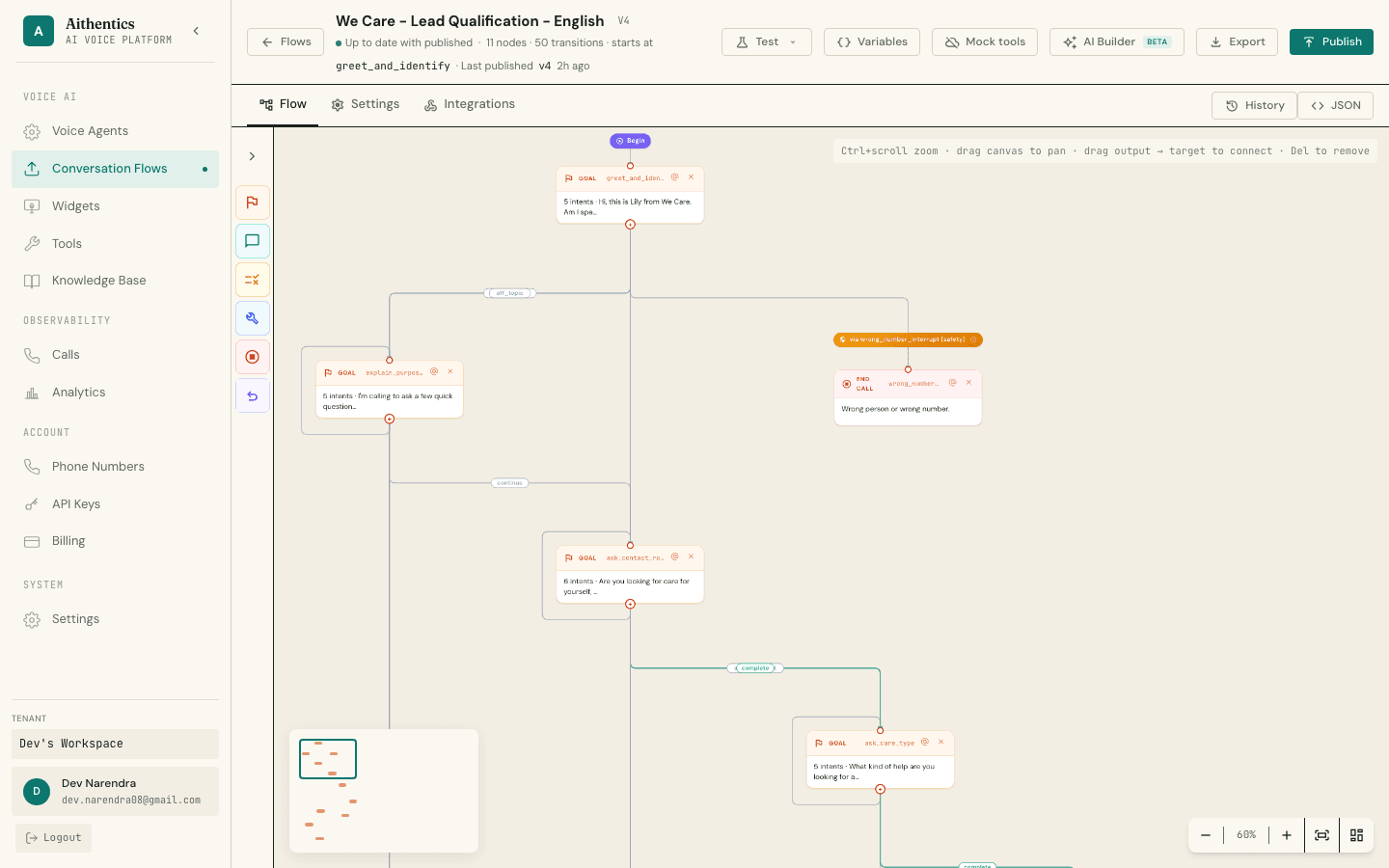
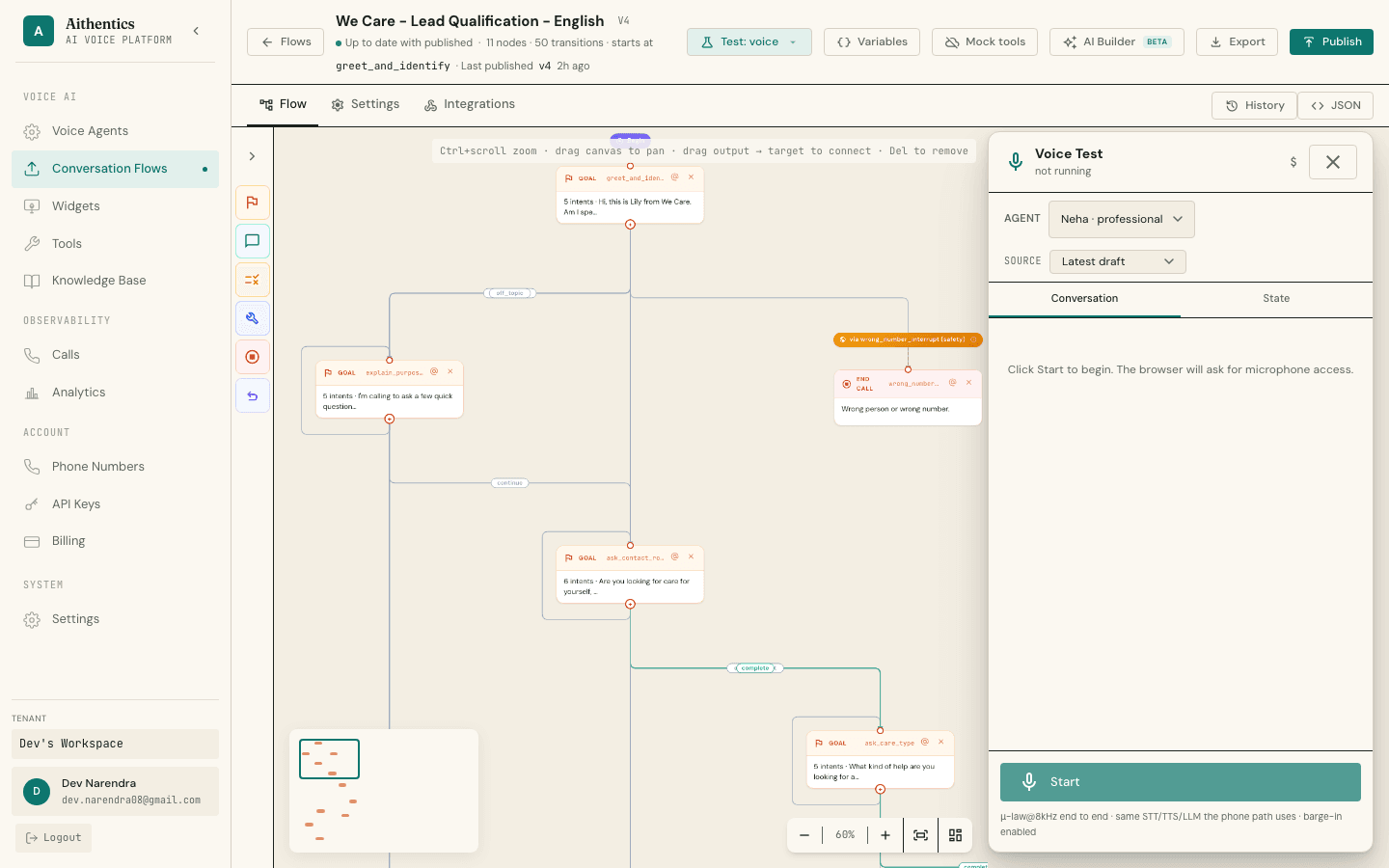
Three test modes. Same engine. No staging gymnastics.
Dry-run text against the engine. Real-mic voice over WebSocket with μ-law 8kHz and barge-in. Or dial a real phone for full end-to-end. Mock tools and seeded variables let you test every branch without external dependencies.
- Text · voice · phone test
- μ-law 8kHz end-to-end
- Barge-in enabled
- Mock tools + variables
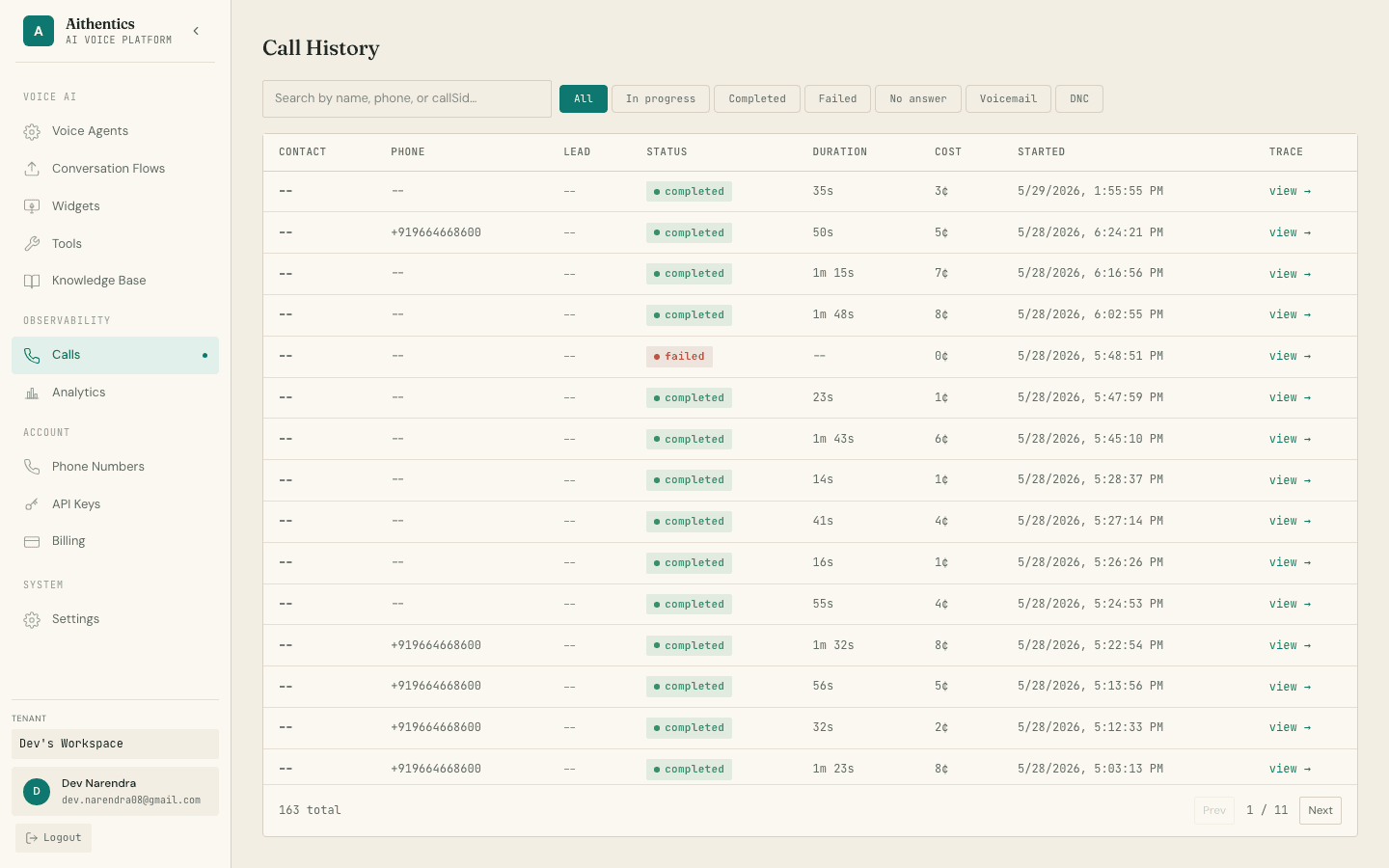
Every call is a trace, every trace is searchable.
Full transcripts, intent traces, latency breakdown, cost per call, drop-off points, replay. Search by phone, name, or callSid. Filter by status: in-progress, completed, failed, no-answer, voicemail, DNC. Pipe the whole stream to your stack via API.
- Per-call trace + replay
- Status + cost + duration
- Search by phone or callSid
- Analytics API
What teams hit before they pick up the platform.
Six problems any team building voice AI products runs into. The platform exists to solve them all in one place.
Slow iteration cycles
Designing conversation flows in code requires engineering bandwidth. Product, CX, and ops teams can't iterate on prompts, intents, or branches without filing a ticket.
Voice agents are hard to test
End-to-end testing means real telephony, real STT, and real TTS — expensive, slow, and noisy. Most teams ship agents without ever testing the full path.
No visibility into conversations
Production voice agents run blind. Without unified transcripts, analytics, and replay, teams can't tell why a flow drops off or where an intent fails.
Five-plus vendors to stitch
Building voice from scratch means integrating LLM, STT, TTS, telephony, and orchestration — each with their own SDK, latency profile, and failure modes.
Single-tenant lock-in
Most voice tools assume one team, one product. No workspaces, no API keys, no programmatic flow management for agencies or platforms shipping voice to their own customers.
Production reliability is hard
Hardening voice for SLA, sub-second latency, barge-in, μ-law 8kHz telephony, and graceful degradation takes months of platform engineering most teams don't have.
Engineered for production reliability — and product-team velocity.
Production signals across deployed agents
Building a voice AI product?
If you're shipping voice agents, conversational AI, or any real-time multi-model system — we'll help you design, build, and operate it.
Turn Your Vision IntoReality
Get a free consultation and discover how we can accelerate your product development with AI-powered solutions.
Launch 40% Faster
AI-powered development reduces time-to-market significantly
Scale with Confidence
Built for growth with enterprise-grade architecture
24-Hour Response
We'll get back to you within 24 hours with a detailed proposal